Run-time Management and Optimisation (Theme 2)
Initial Objectives
- Identify and elaborate mechanisms for exchanging Quality of Service (QoS) requirements between applications and the runtime along with the means through which the runtime system can monitor and control the underlying many-core architecture.
- Design and evaluate adaptive algorithms to provide run-time management of power consumption and faults to achieve a balance between performance, energy usage and resilience.
- Design and evolve a configurable software framework for runtime management of power and faults that extends existing Operating System (OS) capabilities
- Ensure the integrity of the management layer through deployment of formal design and verification methods
- Evaluate the adaptive management framework through extensive experimentation
Introduction
The aim of the High Integrity Run-time Management and Optimisation Theme is to develop sound and effective design principles and mechanisms for runtime management of power and faults to achieve a balance between performance, energy consumption and resilience.
In PRiME we envisage future runtime management mechanisms that allow the resource usage of hundreds or thousands of cores to be continually monitored and adapted at runtime to take account of evolving behaviour. This will allow us to build many-core systems that maximise the opportunities for energy saving and resilience to hardware faults. This must be achieved without putting too much burden on the application-level designers who should remain free to build applications that are not tied to specific architectures. Application designers will provide QoS requirements, on characteristics such as task performance, task priorities, computation accuracy and resource usage (memory, communications) and it will be the responsibility of the runtime management system to ensure that these QoS requirements are correctly satisfied.
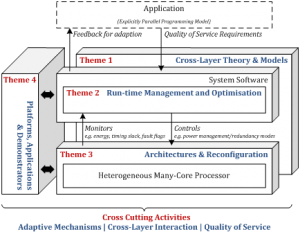
In the figure above we illustrate the three main layers involved in many-core computation with the application software layer at the top, the heterogeneous many-core hardware at the bottom and the system software in-between managing and supporting the execution of application tasks on the hardware. As illustrated, the runtime management mechanism will be an extension of the OS. Runtime management can be viewed as a control problem where the goal in our case is to balance performance, energy usage and resilience by controlling phenomena on the many-core execution platform (such as task allocation and scheduling, node activation, node redundancy, node speed and node voltage scaling). Effective adaptation of the controllable phenomena at the platform level requires regular monitoring of observable phenomena (such as node status, communications traffic, energy usage, circuit timing and state reliability). The degree of control will be driven by QoS requirements coming from the application layer and these QoS requirements may change at runtime. Development of runtime management needs to consider the nature of the interaction with the applications above and with the platform below. To be able to optimize as globally as possible we are developing collaborative mechanisms which incorporate feedback between system layers.
We are building on current developments in many-core operating systems, targeting existing open many-core operating systems and new ones that may arise during the project. Linux is one candidate OS which has been shown to work well, at least for small numbers of cores, and there is evidence that it can scale to larger numbers of cores with appropriate modifications and tuning. Linux has support for power and fault management, though this functionality is fairly coarse grained. Linux supports shared memory for applications and uses sharing, or at least partial replication, of data structures within the OS itself. A promising new development is the Barrelfish many-core OS , http://www.barrelfish.org/, developed between ETH and Microsoft Research, which is an OS especially designed for heterogeneous many-core. Barrelfish is completely distributed in that kernels on each core collaborate through message-passing which should support high degrees of core scaling. Prof T Roscoe, a visiting researcher on PRiME, leads the Barrelfish initiative (assisted by Microsoft Research, one of our industrial collaborators) and is providing us with key expertise as well as contact to the Barrelfish community.
When developing our runtime management mechanisms, we cannot assume a fixed set of many-core architectures. Architectures will evolve during and after the lifetime of PRiME with architectural innovations arising from Theme 3 (Heterogeneous Many-Core Architectures and Hardware Reconfiguration), and externally. Likewise, we cannot assume a fixed set of runtime algorithms for managing power and faults. Using the new theory and models that are developed by Theme 1 (Cross-Layer Theory and Models), this theme is developing new algorithms for adaptive energy management and fault-tolerance, and these will evolve as the project progresses, and with a longer-term vision. It is essential that these new algorithms, and others that may be reported during PRiME’s duration, can be plugged into the runtime environment with minimal effort. The usage scenarios for the many-core embedded systems that we target will vary between application domains and these domains will have different profiles of QoS requirements. For example, a safety-critical system will have much higher reliability requirements than a mobile entertainment device, while the latter is likely to place more emphasis on extending battery life. This high degree of variability in architectures, runtime algorithms and usage scenarios presents a real engineering challenge. Runtime management requires the implementation of complex software for communication, information sharing, coordination and distributed decision making between multiple cores. Implementing software for every specific combination of OS, many-core architecture and runtime algorithm would be very costly. Instead, to deal with this high degree of variability, we are developing an innovative generic software framework for runtime management that can be instantiated for different configurations using software product line techniques.
A runtime management mechanism should not compromise the reliability or performance of the platform it is managing. Because of the potential complexity and interaction with applications and the platform, we are using rigorous design methods that allow us to master the complexity and verify the correctness of our designs in a formal way. The use of formal methods helps to reduce costs by identifying specification and design errors at early development stages when they are cheaper to fix. To analyse the impact of our designs on erformance (speed, energy) we are using a combination of model-based simulation and performance testing using a range of appropriate benchmarks.
This theme is being led by Professor Michael Butler (Southampton), with individual workpackages led by investigators across institutions. The theme’s research is bing tackled by PDRAs at Southampton, Manchester and Newcastle.
Key Outputs and Connections to Other Themes
The outputs from this theme include; definitions of QoS specification mechanisms and of interactions between runtime management and underlying platforms; runtime algorithms for balancing performance, energy efficiency and resilience; a verified generic software framework for runtime management; specific implementations of runtime management; experimental evaluation of runtime management.
Theme 2 is linked to other PRiME themes through the runtime mechanisms developed, which will be informed by the new theory and models produced by Theme 1. Furthermore, the runtime framework will be configurable to interact with the architectures developed in Theme 3, and experimental evaluation of instantiations of the framework will be performed using the platforms and demonstrators developed in Theme 4 (Platforms, Applications and Demonstrators).